
제공 데이터 이해하고 학습데이터/테스트 데이터 load 해보기!
솜씨좋은장씨
·2020. 1. 23. 18:00
라벨링은 어떻게 해야할까?
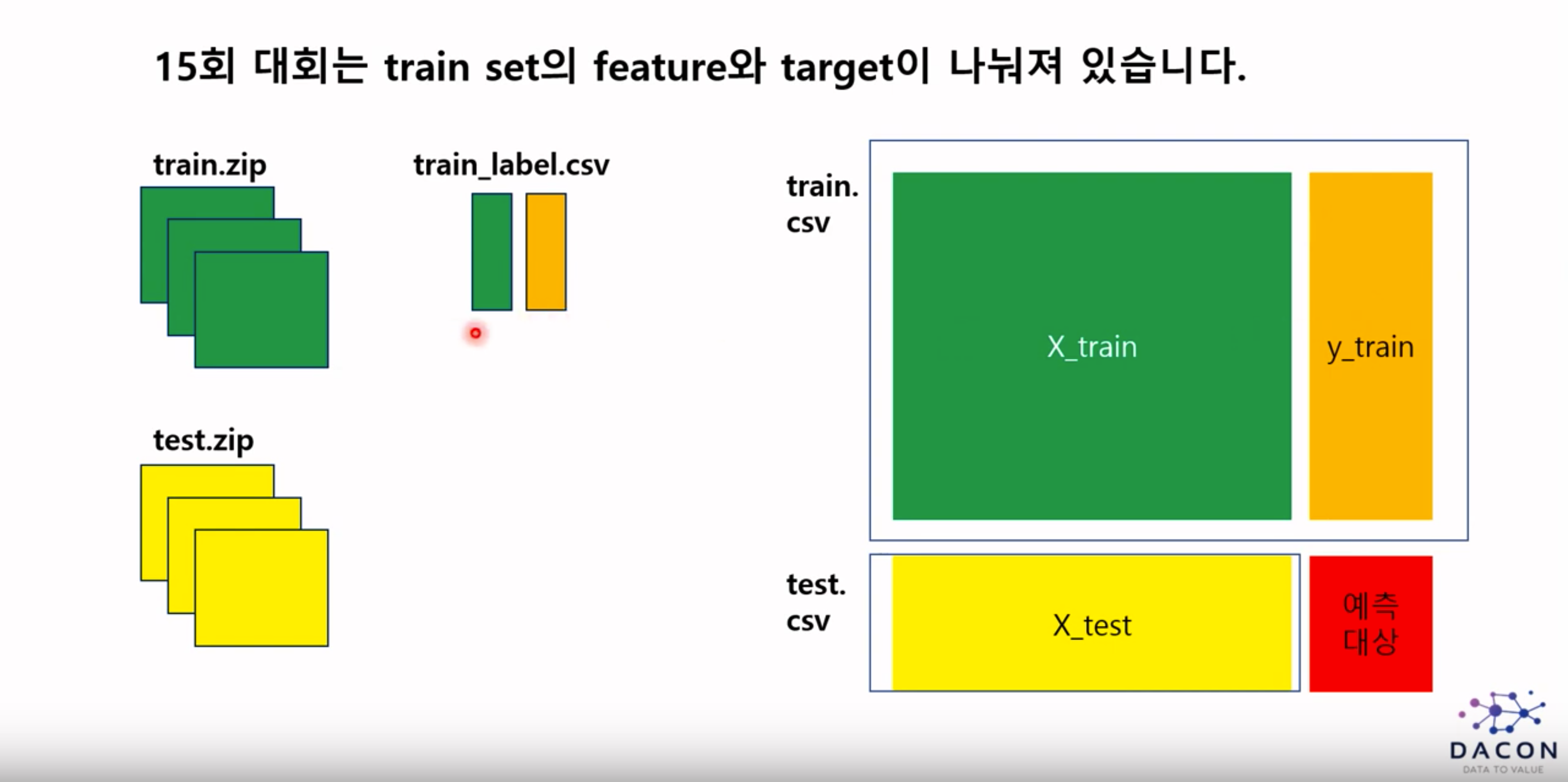
train.zip : 각각의 csv파일은 feature에 대한 내용만 저장되어있음.
train_label.csv : 각각의 csv파일에 대한 label 값은 train_label.csv에 저장되어있음.
참가자가 직접 라벨링을 해주어야함.
train_label.csv파일 내에 각각의 csv파일별로 부여가되는 라벨에 대한 정보가 저장되어있습니다.
즉 만약 1번 csv파일의 라벨값이 29번이라면 29번을 target column에 추가를 해주면 됩니다.
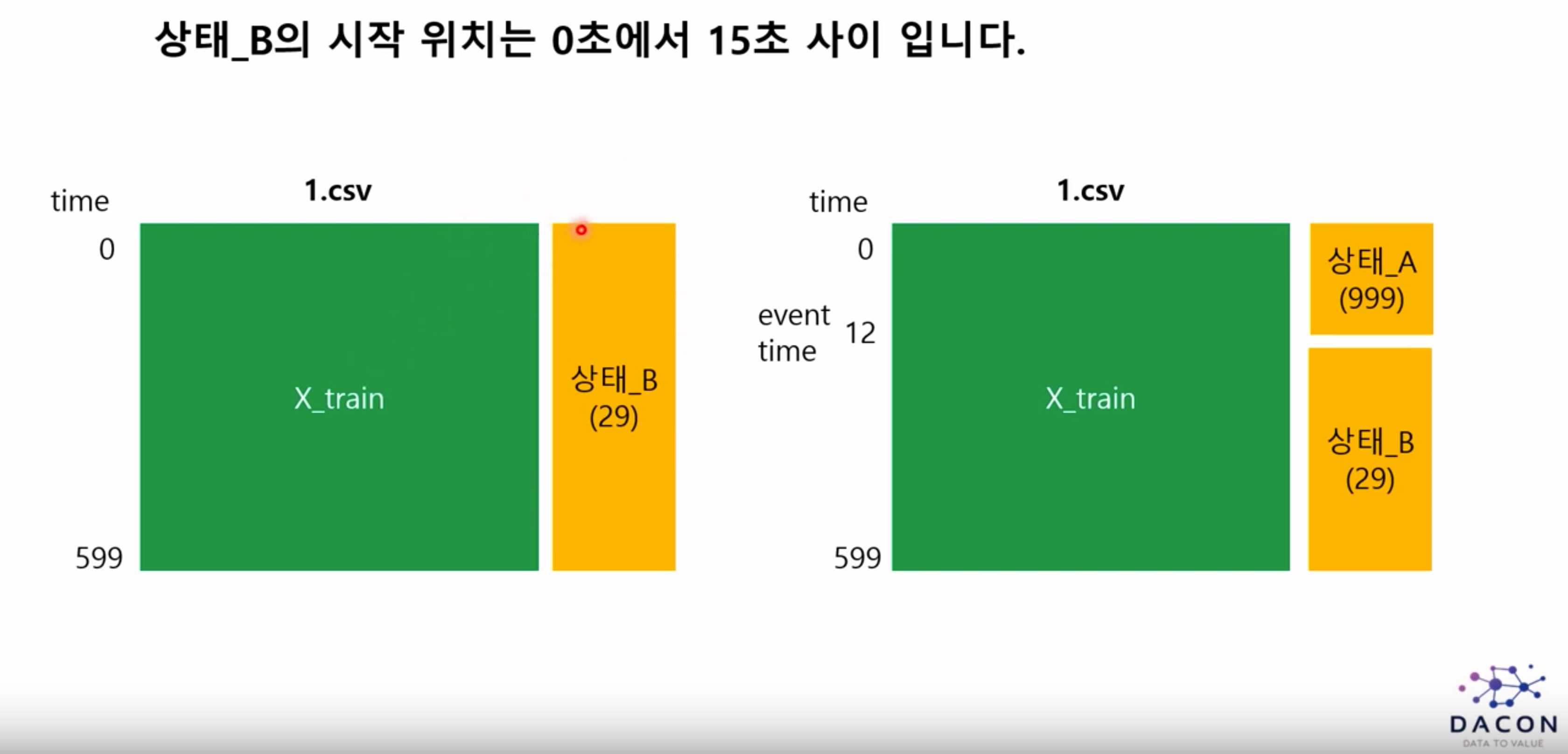
하지만 train_label.csv 내에 있는 라벨 정보는 각각의 파일별 상태 B에 대한 정보를 나타냅니다.
모든 데이터는 상태 A에서 시작하기 때문에 상태 A부분을 반영해주어야합니다.
상태 A에서 발전소가 운영을 시작하다가 중간에 상태 B로 바뀌기 때문에 오른쪽의 그림과 같이
상태 A가 B로 바뀐 시점을 event time이라고 정의하면 event time 이전까지는 상태 A에 대한 라벨링
event time 다음부터 599초까지는 상태 B에 대한 라벨링을 해주면 됩니다.
상태 A에 대한 라벨링은 어떻게 할까
이미 0번부터 197번은 상태 B에 할당이 되어있으므로 0부터 197번이 아닌 숫자를 활용하여 event time 이전의 부분이 상태 B가 아니다라는 것을 명시해주면 됩니다.
여기 사진에서는 999를 예로 들었습니다.
파일별 상태 B의 시작위치 즉 event time은 다를 수 있습니다.
0번 파일은 event time이 10초일 수도 있고 1번 파일은 event time이 12초일 수 있다는 것입니다.
base line 코드는 모든 파일에 대해서 event time을 동일하게 설정하였습니다.
대회 측 공개코드 data_loader 함수 이해하기!
train_dataset

train.zip안에 들어있는 각각의 csv 파일들에 대해서 라벨값을 부여해주고 이것들을 하나의 파일로 합쳐줌으로 써 학습에 사용할 하나의 train_dataset을 만들어주는 역할을 합니다.
test_dataset
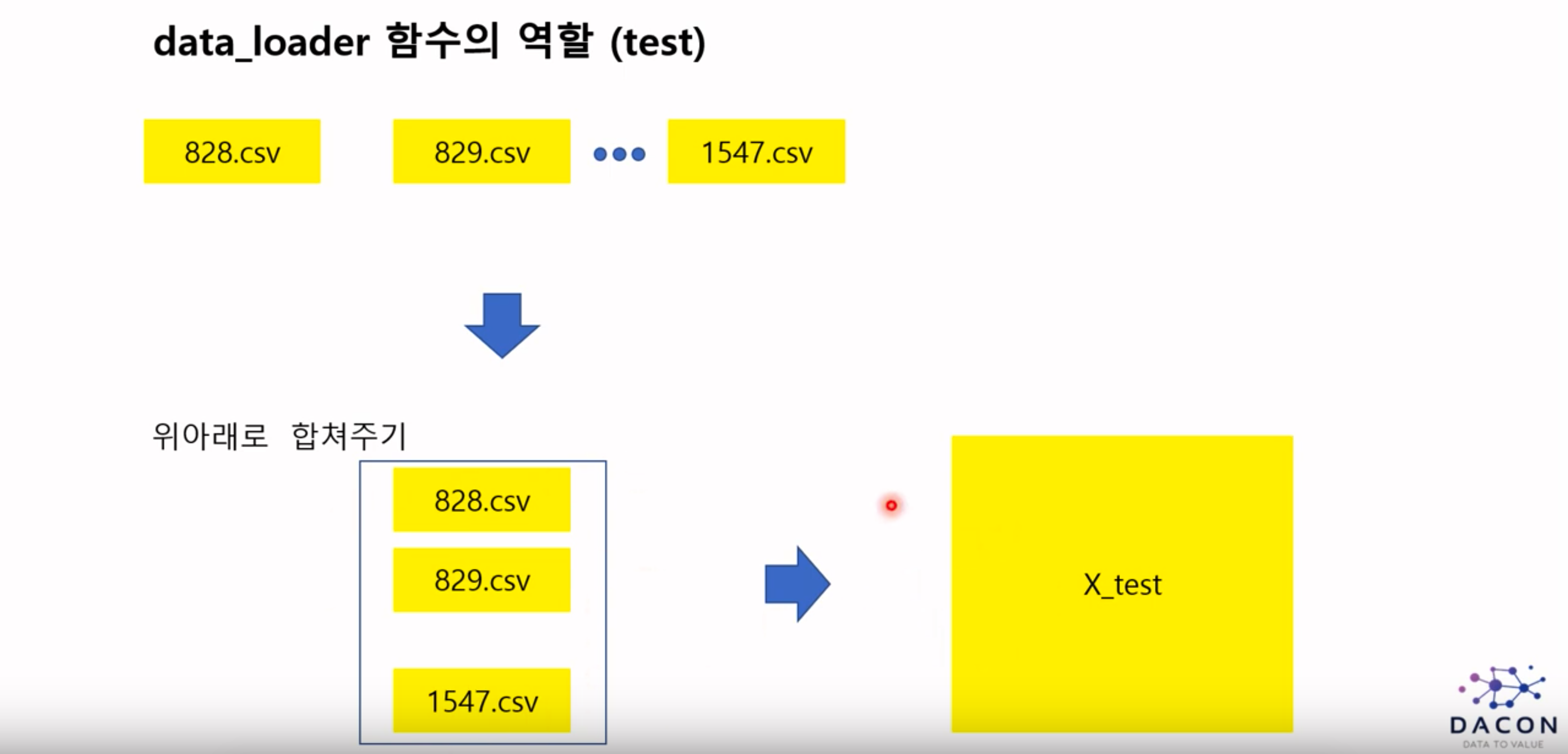
평가에 사용할 데이터를 그저 합쳐주는 역할을 함
코드 ver.1
import os
import pandas as pd
import numpy as np
from multiprocessing import Pool
import multiprocessing
from data_loader import data_loader #data_loader.py 파일을 다운 받아 주셔야 합니다.
from tqdm import tqdm
from functools import partial
def data_loader_all(func, path, train, nrows, **kwargs):
'''
Parameters:
func: 하나의 csv파일을 읽는 함수
path: [str] train용 또는 test용 csv 파일들이 저장되어 있는 폴더
train: [boolean] train용 파일들 불러올 시 True, 아니면 False
nrows: [int] csv 파일에서 불러올 상위 n개의 row
lookup_table: [pd.DataFrame] train_label.csv 파일을 저장한 변수
event_time: [int] 상태_B 발생 시간
normal: [int] 상태_A의 라벨
Return:
combined_df: 병합된 train 또는 test data
'''
# 읽어올 파일들만 경로 저장 해놓기
files_in_dir = os.listdir(path)
files_path = [path+'/'+file for file in files_in_dir]
if train :
func_fixed = partial(func, nrows = nrows, train = True, lookup_table = kwargs['lookup_table'], event_time = kwargs['event_time'], normal = kwargs['normal'])
else :
func_fixed = partial(func, nrows = nrows, train = False)
# 여러개의 코어를 활용하여 데이터 읽기
if __name__ == '__main__':
pool = Pool(processes = multiprocessing.cpu_count())
df_list = list(tqdm(pool.imap(func_fixed, files_path), total = len(files_path)))
pool.close()
pool.join()
# 데이터 병합하기
combined_df = pd.concat(df_list, ignore_index=True)
return combined_df
train_path = 'train'
test_path = 'test'
label = pd.read_csv('train_label.csv')
train = data_loader_all(data_loader, path = train_path, train = True, nrows = 100, normal = 999, event_time = 10, lookup_table = label)
test = data_loader_all(data_loader, path = test_path, train = False, nrows = 60)
코드 ver.2
import os
import pandas as pd
import numpy as np
import multiprocessing # 여러 개의 일꾼 (cpu)들에게 작업을 분산시키는 역할
from multiprocessing import Pool
from functools import partial # 함수가 받는 인자들 중 몇개를 고정 시켜서 새롭게 파생된 함수를 형성하는 역할
from data_loader_v2 import data_loader_v2 # 자체적으로 만든 data loader version 2.0 ([데이콘 15회 대회] 데이터 설명 및 데이터 불러오기 영상 참조)
from sklearn.ensemble import RandomForestClassifier
import joblib # 모델을 저장하고 불러오는 역할
train_folder = 'data/train/'
test_folder = 'data/test/'
train_label_path = 'data/train_label.csv'
train_list = os.listdir(train_folder)
test_list = os.listdir(test_folder)
train_label = pd.read_csv(train_label_path, index_col=0)
def data_loader_all_v2(func, files, folder='', train_label=None, event_time=10, nrows=60):
func_fixed = partial(func, folder=folder, train_label=train_label, event_time=event_time, nrows=nrows)
if __name__ == '__main__':
pool = Pool(processes=multiprocessing.cpu_count())
df_list = list(pool.imap(func_fixed, files))
pool.close()
pool.join()
combined_df = pd.concat(df_list)
return combined_df
train = data_loader_all_v2(data_loader_v2, train_list, folder=train_folder, train_label=train_label, event_time=10, nrows=60)
test = data_loader_all_v2(data_loader_v2, test_list, folder=test_folder, train_label=None, event_time=10, nrows=60)
실제로 한번 실행해보자
데이터 다운로드 바로가기
[산업] 원자력발전소 상태 판단 대회
출처 : DACON - Data Science Competition
dacon.io
실행환경

코드 ver.1 실행 결과

train 결과


일정부분까지 상태 A에 해당하는 999가 들어가고 그 이후에 상태 B에 해당하는 110이 들어가는 것을 볼 수 있습니다.
'경진대회, 공모전 > DACON 원자력발전소 상태 판단 알고리즘 경진대회' 카테고리의 다른 글
| 원자력 발전소 상태 판단 알고리즘 공모전 도전 5일차!(마지막날) (2) | 2020.02.12 |
|---|---|
| 원자력 발전소 상태 판단 알고리즘 공모전 도전 3,4일차! (0) | 2020.02.09 |
| 원자력 발전소 상태 판단 알고리즘 공모전 도전 1, 2일차! (1) | 2020.01.26 |




