
[COMPAS 광양시] 주어진 데이터를 활용하여 행정동별 정보를 모아보자! 2 ( 주차장, 건물, 기타 정보 )
솜씨좋은장씨
·2020. 10. 4. 18:07

데이터 분석 활용 시간
2020년 10월 04일 16시 40분 ~ 18시 10분 ( 총 1시간 30분 소요 )
사용 데이터
02.광양시_주차장_공간정보.csv
05.광양시_대중집합시설_야영장.csv
20.광양시_행정경계(읍면동).geojson
활용 코드
[COMPAS 광양시] 주어진 데이터를 활용하여 행정동별 정보를 모아보자! ( 충전소, 인구 수, 전기차 �
데이터 분석 활용 시간 2020년 10월 01일 12시 30분 ~ 13시 30분 ( 총 1시간 소요 ) 사용 데이터 01.광양시_충전기설치현황.csv 03.광양시_자동차등록현황_격자(100X100).geojson 06.광양시_전기차보급현황(연도
ideans.tistory.com
저번에 진행했던 읍면동 별 충전소, 인구 수, 전기차 보급현황 확인하기에 이어 이번에는
주차장, 건물 정보를 추가로 확인해보기로 했습니다.
parking_spot = pd.read_csv("./data/" + file_list[1])
parking_spot
먼저 제공받은 데이터 중 주차장 관련 데이터를 pandas의 read_csv를 활용하여 열어줍니다.
park_point_dict = {}
for i in tqdm(range(len(parking_spot))):
park_name = parking_spot['주차장명칭'].iloc[i] + " | " + parking_spot['주소'].iloc[i]
park_point_dict[park_name] = {}
park_point_dict[park_name]['Point'] = Point(parking_spot['lon'].iloc[i], parking_spot['lat'].iloc[i])park_point_dict{'인동숲앞 주차장 | 인서리 237-1': {'Point': <shapely.geometry.point.Point at 0x7fafbc67dc18>},
'구터미널주차장 | 중동 1651': {'Point': <shapely.geometry.point.Point at 0x7fafbc621828>},
'구경찰서 주차장 | 읍내리 227-1': {'Point': <shapely.geometry.point.Point at 0x7fafbc621ba8>},
'칠성1지구 | 칠성리 962-1': {'Point': <shapely.geometry.point.Point at 0x7fafbc621c18>},
'칠성1지구 | 칠성리 948-1': {'Point': <shapely.geometry.point.Point at 0x7fafbc6219b0>},
'칠성2지구 | 칠성리 1001-1': {'Point': <shapely.geometry.point.Point at 0x7fafbc6217b8>},
'상설시장내 | 읍내리 252-1': {'Point': <shapely.geometry.point.Point at 0x7fafbc621630>},
'칠성2지구(매화마을앞) | 구산리 767-1': {'Point': <shapely.geometry.point.Point at 0x7fafbc6215c0>},
'칠성2지구(파랑새유치원앞) | 칠성리 996': {'Point': <shapely.geometry.point.Point at 0x7fafbc621438>},
'칠성1지구 | 칠성리 924-1': {'Point': <shapely.geometry.point.Point at 0x7fafbc6213c8>},
'수성당 인근 | 읍내리 178-2': {'Point': <shapely.geometry.point.Point at 0x7fafbc621240>},
'인서지구주거환경개선 | 칠성리 491-22': {'Point': <shapely.geometry.point.Point at 0x7fafbc6211d0>},
'성보장 | 인동리 400': {'Point': <shapely.geometry.point.Point at 0x7fafbc621fd0>},
...데이터 속 위도, 경도 정보를 활용하여 각 주차장 별 Point를 생성하고 이를 dictionary로 만들어 줍니다.
umds = []
park_point_dict_keys = list(park_point_dict.keys())
umd_keys = list(umd_polys.keys())
for key in park_point_dict_keys:
for umd_key in umd_keys:
umd_ploy_lists = umd_polys[umd_key]
for umd_polygon in umd_ploy_lists:
if umd_polygon.contains(park_point_dict[key]['Point']) == True:
park_point_dict[key]['umd'] = umd_key
umds.append(umd_key)
breakpark_point_dict{'인동숲앞 주차장 | 인서리 237-1': {'Point': <shapely.geometry.point.Point at 0x7fafbc67dc18>,
'umd': '광양읍'},
'구터미널주차장 | 중동 1651': {'Point': <shapely.geometry.point.Point at 0x7fafbc621828>,
'umd': '중마동'},
'구경찰서 주차장 | 읍내리 227-1': {'Point': <shapely.geometry.point.Point at 0x7fafbc621ba8>,
'umd': '광양읍'},
'칠성1지구 | 칠성리 962-1': {'Point': <shapely.geometry.point.Point at 0x7fafbc621c18>,
'umd': '광양읍'},
'칠성1지구 | 칠성리 948-1': {'Point': <shapely.geometry.point.Point at 0x7fafbc6219b0>,
'umd': '광양읍'},
'칠성2지구 | 칠성리 1001-1': {'Point': <shapely.geometry.point.Point at 0x7fafbc6217b8>,
'umd': '광양읍'},
'상설시장내 | 읍내리 252-1': {'Point': <shapely.geometry.point.Point at 0x7fafbc621630>,
'umd': '광양읍'},
...여기서 umds 에 저장한 정보를 바탕으로 각 읍면동 별로 주차장이 몇개씩 존재하는지 확인해봅니다.
from collections import Counter
umd_cnt = Counter(umds)
umd_cntCounter({'광양읍': 76,
'중마동': 73,
'골약동': 4,
'광영동': 26,
'태인동': 9,
'금호동': 6,
'옥룡면': 8,
'옥곡면': 12,
'진상면': 7,
'진월면': 6,
'봉강면': 8})이를 이전에 만들었던 데이터 프레임에 합쳐줍니다.
new_umd_infos_df['주차장 개수'] = [0] * len(new_umd_infos_df['읍면동'])
for i in tqdm(range(len(new_umd_infos_df['읍면동']))):
if new_umd_infos_df['읍면동'].iloc[i] in list(umd_cnt.keys()):
new_umd_infos_df['주차장 개수'].iloc[i] = dict(umd_cnt)[new_umd_infos_df['읍면동'].iloc[i]]
new_umd_infos_df
camp_df = pd.read_csv("./data/" + file_list[4])
camp_df
new_umd_infos_df['야영장 휴양림 개수'] = [0] * len(new_umd_infos_df['읍면동'])
address = list(camp_df['주소'])
for i in tqdm(range(len(address))):
for j in range(len(new_umd_infos_df['읍면동'])):
if new_umd_infos_df['읍면동'].iloc[j] == address[i].split()[1]:
new_umd_infos_df['야영장 휴양림 개수'].iloc[j] = new_umd_infos_df['야영장 휴양림 개수'].iloc[j] + 1
breaknew_umd_infos_df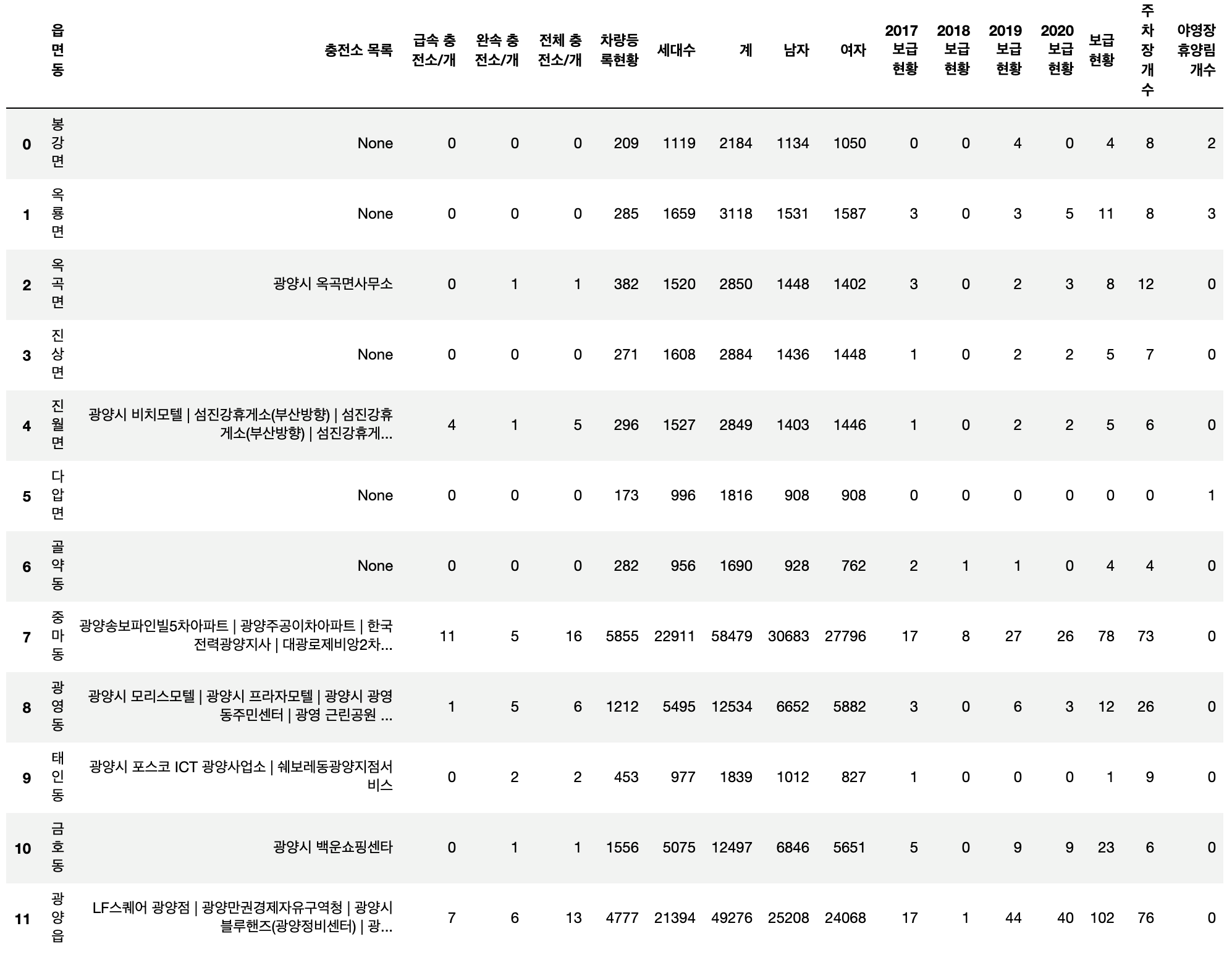
execer_df = pd.read_csv("./data/" + file_list[3])
execer_df
execr_keys = list(execer_df['업종'].unique())
execr_list = []
for i in tqdm(range(len(execr_keys))):
temp_df = execer_df[execer_df['업종'] == execr_keys[i]]
execr_list.append(temp_df)execer_dict = {}
for i in tqdm(range(len(execr_keys))):
if execr_keys[i] not in list(execer_dict.keys()):
execer_dict[execr_keys[i]] = {}
execer_dict[execr_keys[i]]['Points'] = []
temp_df = execr_list[i]
for j in range(len(temp_df['업종'])):
execer_dict[execr_keys[i]]['Points'].append(Point(temp_df['lon'].iloc[j], temp_df['lat'].iloc[j]))execer_dict{'가상체험 체육시설업': {'Points': [<shapely.geometry.point.Point at 0x7fafbc449cf8>,
<shapely.geometry.point.Point at 0x7fafbc449b70>,
<shapely.geometry.point.Point at 0x7fafbc449898>]},
'골프연습장': {'Points': [<shapely.geometry.point.Point at 0x7fafbc449860>,
<shapely.geometry.point.Point at 0x7fafbc449c50>,
<shapely.geometry.point.Point at 0x7fafbc4497f0>,
<shapely.geometry.point.Point at 0x7fafbc4490f0>,
<shapely.geometry.point.Point at 0x7fafbc449dd8>,
...for key in list(execer_dict.keys()):
umds = []
for point in execer_dict[key]['Points']:
umd_keys = list(umd_polys.keys())
for umd_key in umd_keys:
umd_ploy_lists = umd_polys[umd_key]
for umd_polygon in umd_ploy_lists:
if umd_polygon.contains(point) == True:
umds.append(umd_key)
break
execer_dict[key]['umds'] = umds
execer_dict{'가상체험 체육시설업': {'Points': [<shapely.geometry.point.Point at 0x7fafbc449cf8>,
<shapely.geometry.point.Point at 0x7fafbc449b70>,
<shapely.geometry.point.Point at 0x7fafbc449898>],
'umds': ['중마동', '중마동', '옥곡면']},
'골프연습장': {'Points': [<shapely.geometry.point.Point at 0x7fafbc449860>,
<shapely.geometry.point.Point at 0x7fafbc449c50>,
...for key in list(execer_dict.keys()):
new_umd_infos_df[key] = [0] * len(new_umd_infos_df['읍면동'])
for umd in execer_dict[key]['umds']:
for i in range(len(new_umd_infos_df['읍면동'])):
if new_umd_infos_df['읍면동'].iloc[i] == umd:
new_umd_infos_df[key].iloc[i] = new_umd_infos_df[key].iloc[i] + 1
breaknew_umd_infos_df
여기까지 구축한 데이터를 히트맵으로 그려 상관관계를 알아보았습니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['figure.figsize'] = [60, 30]
plt.rcParams['font.family'] = "NanumGothic"
correlations = new_umd_infos_df.corr() # plt.figure(figsize = (14, 12)) # Heatmap of correlations
sns.heatmap(correlations, cmap = plt.cm.RdYlBu_r, vmin = 0.2, annot = True, vmax = 0.9)
plt.title('Correlation Heatmap');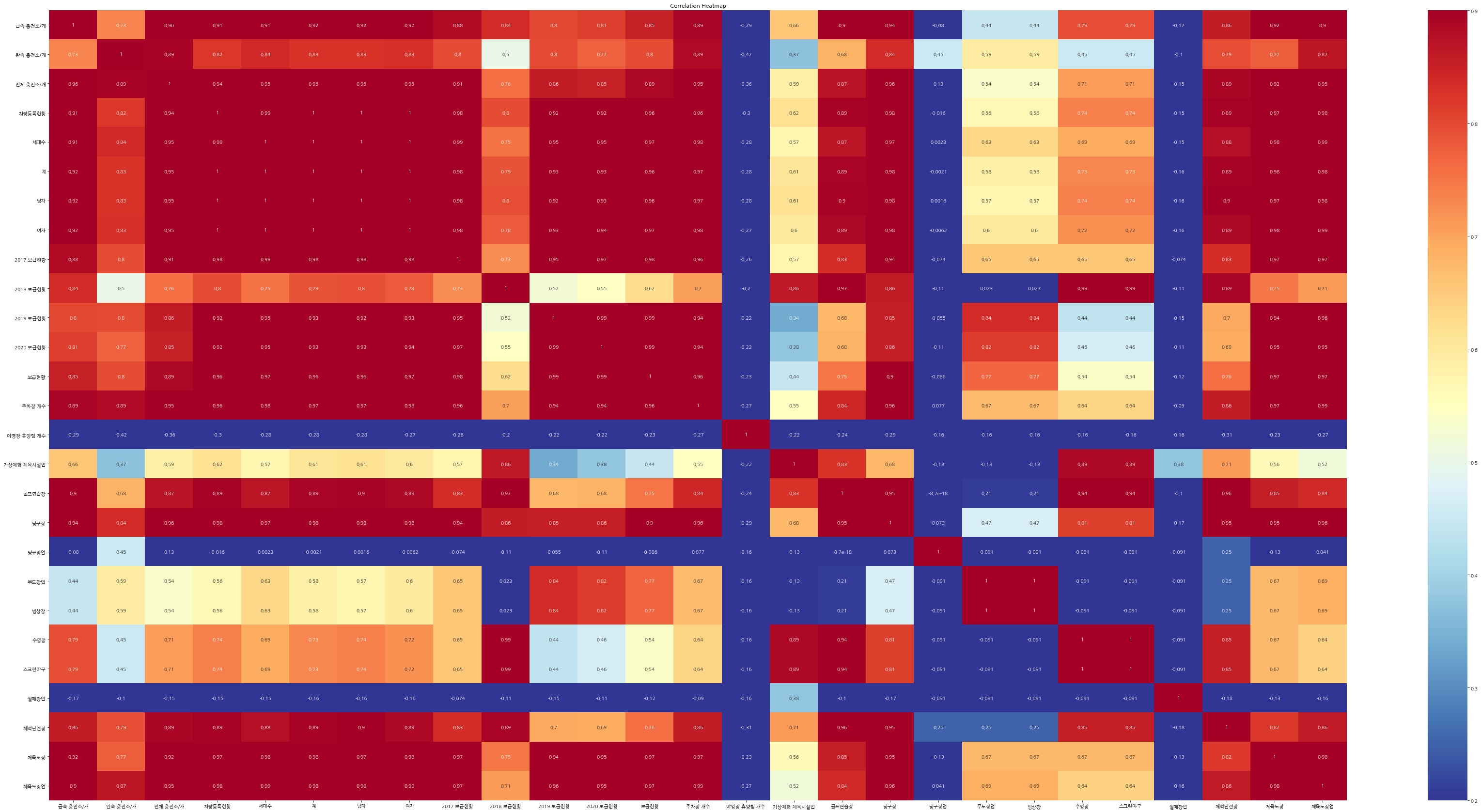
'경진대회, 공모전 > COMPAS 광양시 전기자동차 충전소 최적입지 선정' 카테고리의 다른 글
| [COMPAS 광양시] 100x100 격자로 나누어져 있는 정보에 여러 정보들 추가로 합쳐보기! ( 주차장, 자동차등록현황, 건물(연면적), 개발행위제한구역, 행정경계, 고도) (0) | 2020.10.25 |
|---|---|
| [COMPAS 광양시] 2019년 환경부 충전인프라 설치 지침 읽어보기 (0) | 2020.10.03 |
| [COMPAS 광양시] 주어진 데이터를 활용하여 행정동별 정보를 모아보자! ( 충전소, 인구 수, 전기차 보급현황 ) (7) | 2020.10.01 |
| [COMPAS 광양시] 현재 설치 되어있는 전기차 충전소에 대해 알아보자! (0) | 2020.09.27 |
| [COMPAS 광양시] 100 x 100 격자 데이터 활용 각 읍면동별 차량 등록 정보 데이터 만들기 (0) | 2020.09.26 |





