
python 카테고리 나누기 / pydeck을 이용하여 스테이션별 이용량 파악하기
프롬씬
·2020. 9. 11. 13:00
3. 맴버십 비맴버십으로 나눠보기
#MEMB_DIV 회원 구분(비회원은 99이며 나머지는 정회원)
riding_data.MEMB_DIV.value_counts() 
#비회원인 99는 MEMB_NO가 0으로 뜬다.
riding_membership = riding_data[["MEMB_DIV", "MEMB_NO", "Difference"]]
riding_membership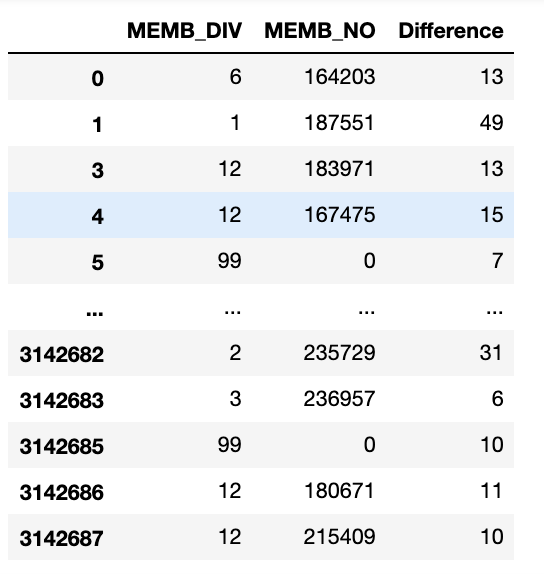
#회원들을 1로 바꾸고 비회원은 99로 냅둔다.
riding_membership.loc[riding_membership["MEMB_DIV"] != 99, "MEMB_DIV"] = 1 riding_membership["membership"] = riding_membership.MEMB_DIV.replace({1:"membership", 99:"non_membership"})
riding_membership.head() 
#멤버십 이용자가 많음
riding_membership.membership.value_counts() 
#단기시간 단위로 잘라보면 non_membership인 대여자들이 30~1시간 안으로 대여를 많이 한다.
plt.figure(figsize=(12, 5)) # Make the figure wider than default (12cm wide by 5cm tall)
sns.boxenplot(x="membership", y="Difference", data=riding_membership)
plt.ylim(0,100) 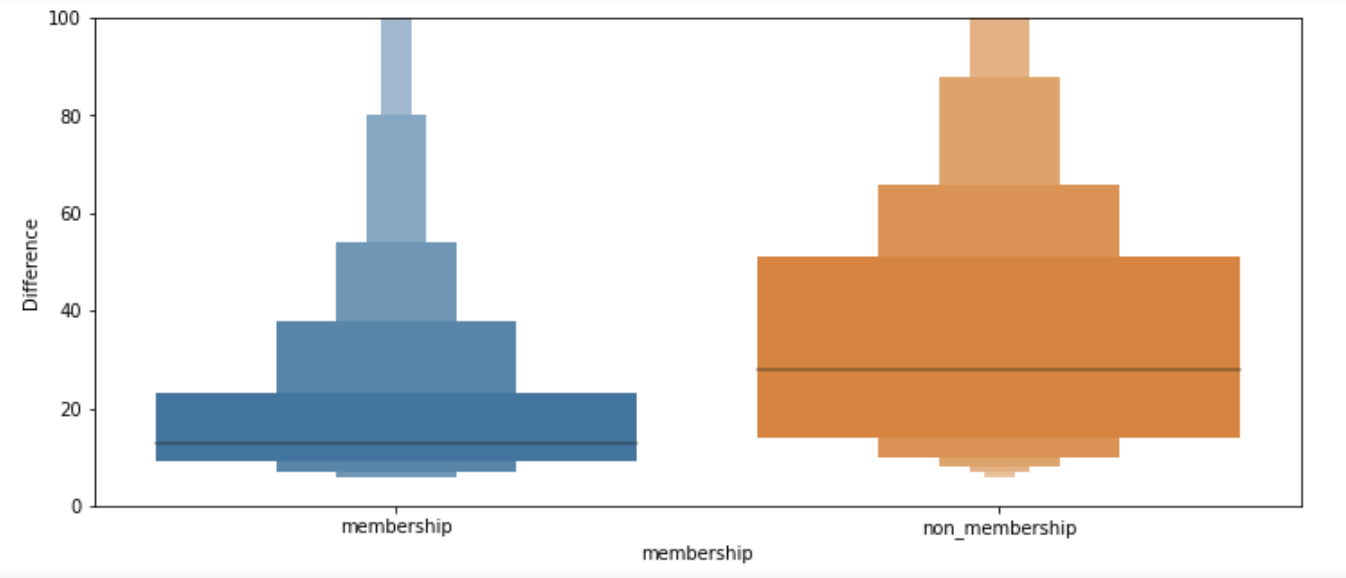
#membership은 이상치가 non_membership보다 (중장기대여)
plt.figure(figsize=(12, 5)) # Make the figure wider than default (12cm wide by 5cm tall)
sns.boxplot(x="membership", y="Difference", data=riding_membership)
riding_data["membership"] = riding_membership["membership"]riding_data에 멤버십칼럼 붙히기
4. 멤버쉽별 사용자 비교
human_active = riding_data[["LEAS_DATE","RTN_DATE","MEMB_DIV","MEMB_NO",'TEMP_MEMB_NO','Difference','timegrp','membership']]
human_active 원하는 칼럼을 모아서 human_active 데이터 만들어주기
human_active.timegrp.astype("object") 
mem_time=human_active.groupby(["membership"])["timegrp"].value_counts()
mem_time 
mem_time = mem_time.unstack()
mem_time = mem_time.fillna(0)
mem_time = mem_time.apply(lambda x: x/x.sum(), axis=1)
#mem_time = mem_time.to_string(float_format="%.3f") 
plt.figure(figsize=(36,15))
sns.boxplot(x="timegrp", y="Difference", hue="membership", data=human_active)
plt.ylim(0,300) 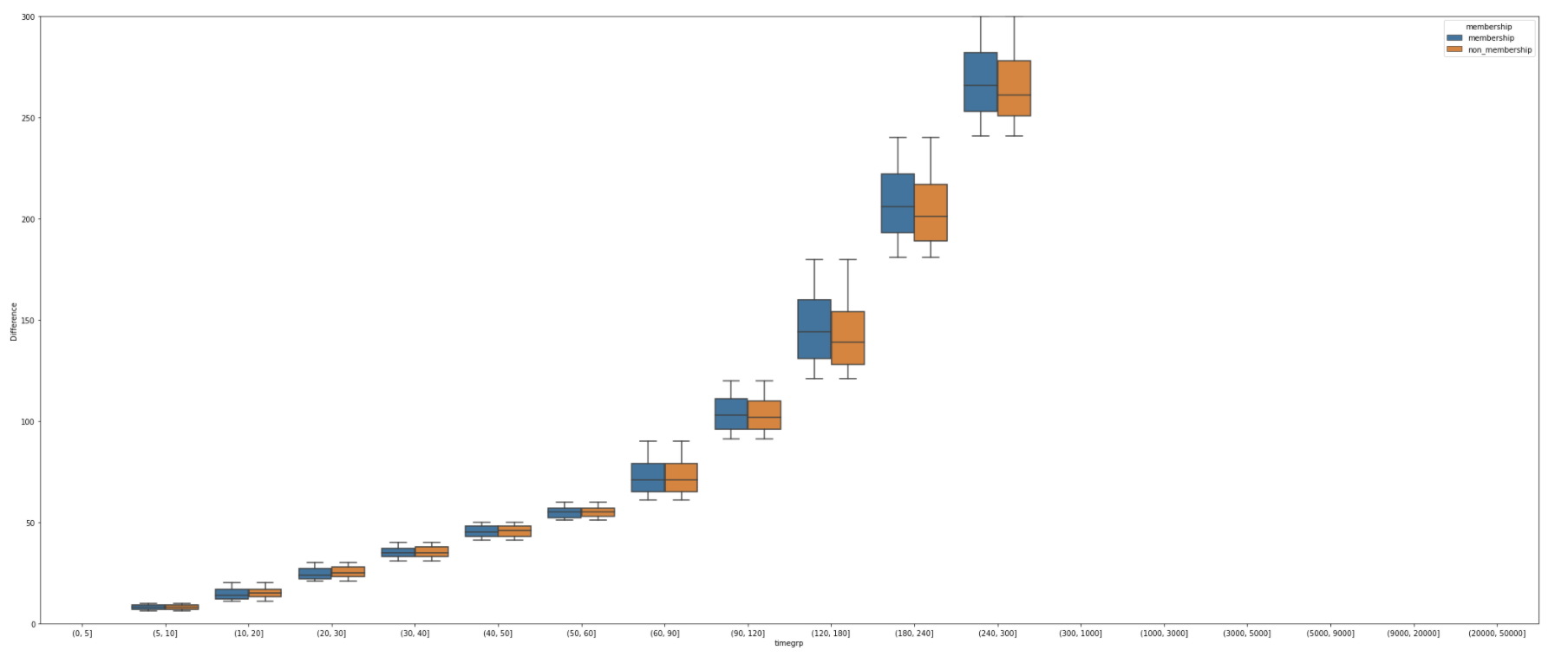
plt.figure(figsize=(36,15))
sns.boxplot(x="membership", y="Difference", hue="timegrp", data=human_active)
#120분 내 애들 비교하기
plt.ylim(0,300) 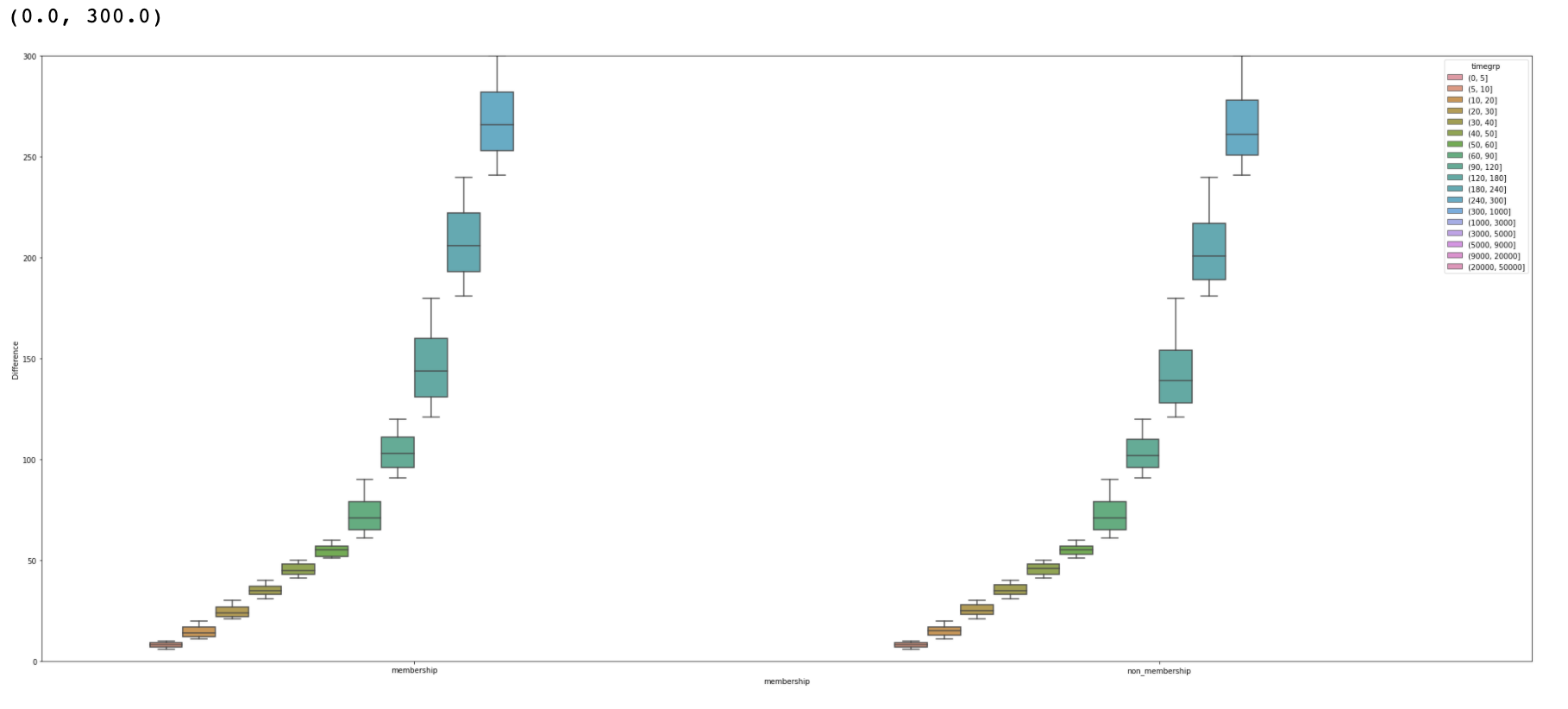
5. 멤버쉽과 비멤버쉽의 이용량을 통한 "빌린장소-반납장소" 간의 빈도 시각화하기.
콤파스에 나와있는 데이터를 바탕으로 이용빈도를 시각화해보겠습니다.
non_membership_data= riding_data.loc[riding_data["MEMB_DIV"] == 99, :]
non_membership_data.shape 
membership_data = riding_data.loc[~riding_data.MEMB_DIV.isin([99]), :]
membership_data.shape 
non_membership = non_membership_data[["LEAS_NO","LEAS_STAT","LEAS_STATION","RTN_STATION","MEMB_DIV"
,"Difference","timegrp"]]
non_membership membership = membership_data[["LEAS_NO","LEAS_STAT","LEAS_STATION","RTN_STATION","MEMB_DIV"
,"Difference","timegrp"]]
membership 
필요한 데이터를 뽑습니다.
membership["counts"] = 1
membership counts 라는 데이터를 이용해 하나의 트랙젝션마다 1을 부여해 줍니다.
membership_counts = membership[membership['counts'] == 1].groupby(['LEAS_STATION', 'RTN_STATION']).size().to_frame().reset_index()
membership_counts.rename({0: "이용량"}, axis=1, inplace=True)
membership_counts 
대여 스테이션과 반납 스테이션이 묶여 데이터에서 한 쌍마다 이루어진 이용량을 계산해줍니다.
ver_1 = pd.merge(membership_counts, bicycle_data, left_on="LEAS_STATION", right_on="station_id", how="inner") bicycle_data는 정류장과 위도, 경도가 있는 데이터 입니다.
ver_2 = pd.merge(ver_1,bicycle_data,left_on="RTN_STATION", right_on="station_id", how="inner") 이를 이용해 각 스테이션마다 위치를 머지해줍니다.
ver_2.columns ver_2.columns =['LEAS_STATION', 'RTN_STATION', '이용량', 'station_id_leas',
'station_name_leas', 'nums_leas', 'latitude_leas', 'longitude_leas', 'station_id_rtn',
'station_name_rtn', 'nums_rtn', 'latitude_rtn', 'longitude_rtn'] max_value = ver_2['이용량'].max()
df_from_to1_topn = ver_2.sort_values('이용량', ascending=False)[:10]
df_from_to1_topn 가장 이용량이 많은 10군데입니다.

상위 100개의 데이터만 보겠습니다.
max_value = ver_2['이용량'].max()
df_from_to1_topn = ver_2.sort_values('이용량', ascending=False)[:100]
data = []
for i in df_from_to1_topn.itertuples():
station_from = getattr(i, 'station_id_leas')
station_to = getattr(i, 'station_id_rtn')
from_lon = getattr(i, 'longitude_leas')
from_lat = getattr(i, 'latitude_leas')
to_lon = getattr(i, 'longitude_rtn')
to_lat = getattr(i, 'latitude_rtn')
value = getattr(i, '이용량')
data.append({
"from": [from_lon, from_lat],
"to": [to_lon, to_lat],
"경로": "%s -> %s"%(station_from, station_to),
"이용": value,
"width": 50 * (value / max_value) + 1,
"from_color": [255,20,0, 255, value / max_value*255],
"to_color": [0,255, 20, value / max_value*255],
})access_token = 'pk.eyJ1IjoiZGFlZG9sIiwiYSI6ImNqZGpqbmpnYzFscm8yd245YXM5MWQxeGgifQ.ACxKlSjUthNpixmVX2faMw'
view_options = {
'center': [126.762162, 37.663241],
'zoom': 11,
'bearing': 0,
'pitch': 60,
'style': 'mapbox://styles/mapbox/dark-v9',
'access_token': access_token
}m = deckgl.Map(**view_options)
arc_layer = deckgl.ArcLayer(data,
getSourcePosition='obj => obj.from',
getTargetPosition='obj => obj.to',
getSourceColor='obj => obj.from_color',
getTargetColor='obj => obj.to_color',
getWidth='obj => obj.width',
pickable=True,
tooltip=["경로", "이용"])
m.add(arc_layer)
m.show()

마찬가지로 비멤버쉽도 동일하게 해줍니다.
non_membership = non_membership_data[["LEAS_NO","LEAS_STAT","LEAS_STATION","RTN_STATION","MEMB_DIV"
,"Difference","timegrp"]]
non_membershipnon_membership["counts"] = 1
non_membership
non_membership_counts = non_membership[non_membership['counts'] == 1].groupby(['LEAS_STATION', 'RTN_STATION']).size().to_frame().reset_index()
non_membership_counts.rename({0: "이용량"}, axis=1, inplace=True)
non_membership_countsver_3 = pd.merge(non_membership_counts, bicycle_data, left_on="LEAS_STATION", right_on="station_id", how="inner")ver_4 = pd.merge(ver_3, bicycle_data,left_on="RTN_STATION", right_on="station_id", how="inner")ver_4.columns =['LEAS_STATION', 'RTN_STATION', '이용량', 'station_id_leas',
'station_name_leas', 'nums_leas', 'latitude_leas', 'longitude_leas', 'station_id_rtn',
'station_name_rtn', 'nums_rtn', 'latitude_rtn', 'longitude_rtn']max_value = ver_4['이용량'].max()
df_from_to1_topn_1 = ver_4.sort_values('이용량', ascending=False)[:10]
df_from_to1_topn_1상위 100개의 데이터만 보여줍니다.
max_value = ver_4['이용량'].max()
df_from_to1_topn_1 = ver_4.sort_values('이용량', ascending=False)[:100]
data = []
for i in df_from_to1_topn_1.itertuples():
station_from = getattr(i, 'station_id_leas')
station_to = getattr(i, 'station_id_rtn')
from_lon = getattr(i, 'longitude_leas')
from_lat = getattr(i, 'latitude_leas')
to_lon = getattr(i, 'longitude_rtn')
to_lat = getattr(i, 'latitude_rtn')
value = getattr(i, '이용량')
data.append({
"from": [from_lon, from_lat],
"to": [to_lon, to_lat],
"경로": "%s -> %s"%(station_from, station_to),
"이용": value,
"width": 50 * (value / max_value) + 1,
"from_color": [255,20,0, 255, value / max_value*255],
"to_color": [0,255, 20, value / max_value*255],
})access_token = 'pk.eyJ1IjoiZGFlZG9sIiwiYSI6ImNqZGpqbmpnYzFscm8yd245YXM5MWQxeGgifQ.ACxKlSjUthNpixmVX2faMw'
view_options = {
'center': [126.762162, 37.663241],
'zoom': 11,
'bearing': 0,
'pitch': 60,
'style': 'mapbox://styles/mapbox/dark-v9',
'access_token': access_token
}m = deckgl.Map(**view_options)
arc_layer = deckgl.ArcLayer(data,
getSourcePosition='obj => obj.from',
getTargetPosition='obj => obj.to',
getSourceColor='obj => obj.from_color',
getTargetColor='obj => obj.to_color',
getWidth='obj => obj.width',
pickable=True,
tooltip=["경로", "이용"])
m.add(arc_layer)
m.show()
'경진대회, 공모전 > COMPAS 고양시 공공자전거 스테이션 최적 위치 선정' 카테고리의 다른 글
| "피프틴" 태그가 포함된 인스타그램 게시물 개수 추이와 실제 사용량 비교해보기 (2) | 2020.09.12 |
|---|---|
| python boxplot을 통해 데이터 빈도 알아보기/ 고양시 운영이력 데이터 살펴보기 (0) | 2020.09.11 |
| [COMPAS 고양시] 데이터 시각화 해보기 ( feat. python, folium ) (0) | 2020.08.01 |




